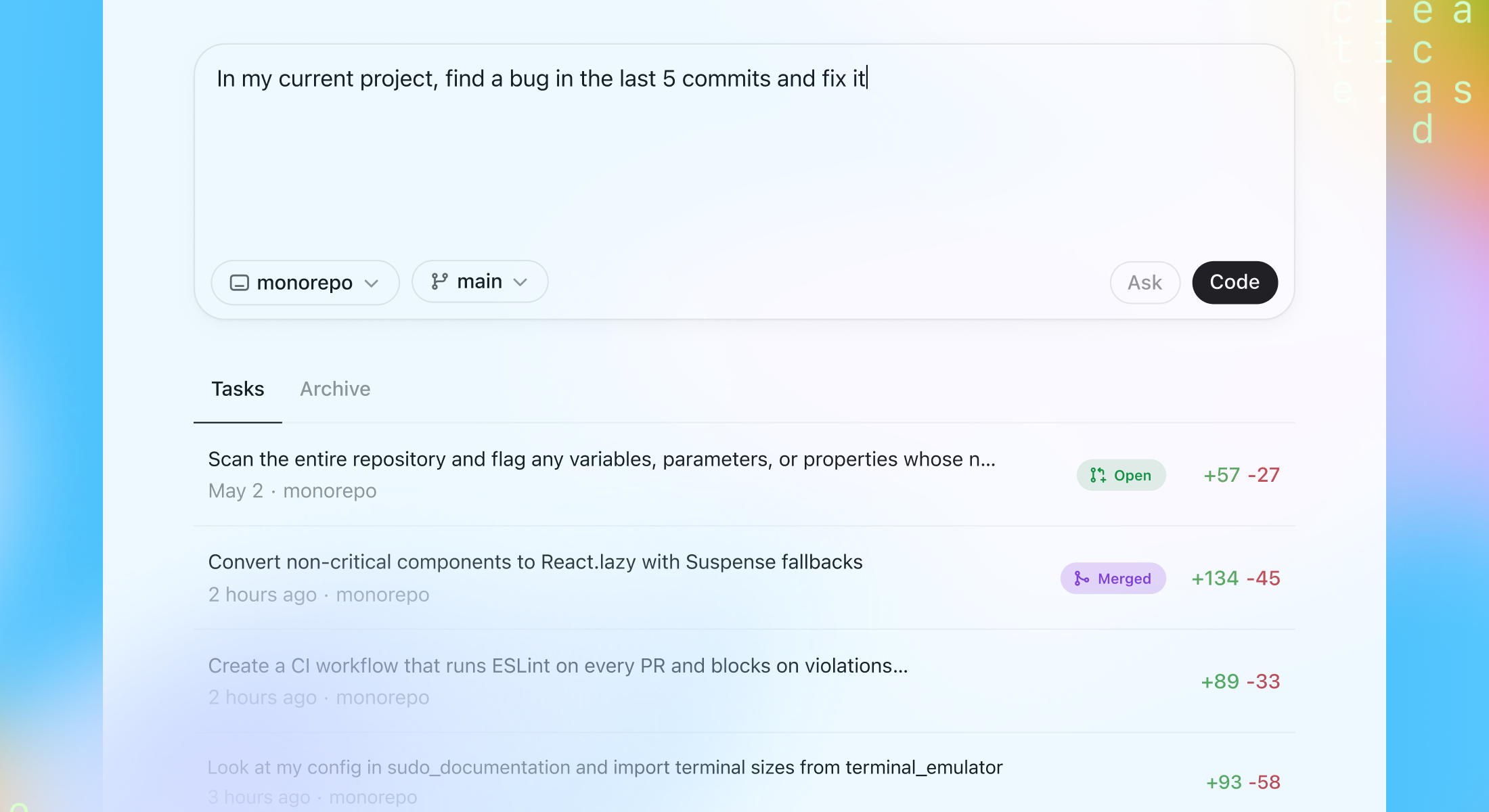
Почему Codex важен не как чат, а как отдельный исполнитель
Самый сильный сдвиг в Codex не в том, что модель умеет писать код, а в том, что OpenAI упаковала ее в отдельный контур исполнения. В майском анонсе прямо сказано: каждая задача запускается в собственной sandbox-среде, заранее загруженной вашим репозиторием. Агент может читать и править файлы, запускать тесты, линтеры и type checkers, а потом вернуть не разговор, а проверяемый результат. Для зрелой инженерной команды это принципиальная разница.
Обычный IDE-чат чаще всего ломается на двух вещах. Он либо не видит реальную среду проекта, либо не оставляет внятного следа того, что сделал. Codex бьет именно по этим слабым местам. OpenAI подчеркивает, что результат сопровождается terminal logs, test outputs и diff, а поведение агента можно направлять через AGENTS.md. Это уже не просто удобная генерация фрагмента кода, а попытка построить управляемую форму делегирования.
Где облачный агент сильнее обычного copiloting-подхода
Наиболее убедительный сценарий Codex - хорошо ограниченная, но достаточно длинная работа, которую жалко держать в голове вручную. Это может быть разбор багрепорта, подготовка тестов, рефакторинг, triage, сведение контекста по инциденту, фоновая проверка старого куска системы или подготовка стартового исправления для code review. Там, где человек иначе сам бы собрал тикет, куски логов, локальные воспроизведения, diff и список проверок, агент действительно экономит внимание.
Но этот выигрыш не бесплатный. Сам OpenAI пишет, что задача в Codex обычно завершается не мгновенно, а в диапазоне примерно от одной до тридцати минут в зависимости от сложности. Это значит, что Codex плохо подходит для режима "я сижу в редакторе и жду мгновенную реакцию на каждое слово". Его сильная сторона - фоновое выполнение и возврат готовой работы. Если команда путает эти два режима, она почти наверняка разочаруется.
Почему связка app и editor уже важнее разового prompt
Публичная страница продукта уже подает Codex не только как кодовый инструмент, но и как систему, которая живет сразу на нескольких поверхностях: отдельное приложение, редактор, терминал. Это важный сигнал. OpenAI явно двигает продукт от одиночного облачного эксперимента к сквозному workflow, где одна и та же задача может стартовать в одной среде, а затем продолжаться в другой без ручного переноса контекста.
Для команд это практично по двум причинам. Во-первых, не каждая задача начинается в IDE: часть работ рождается из инцидента, тикета, таблицы, документа или переписки. Во-вторых, даже удачный агент не отменяет финальный review человеком. Чем лучше Codex вписывается в переход от постановки задачи к реальной доработке в редакторе, тем меньше он выглядит игрушкой и тем больше - инфраструктурным слоем.
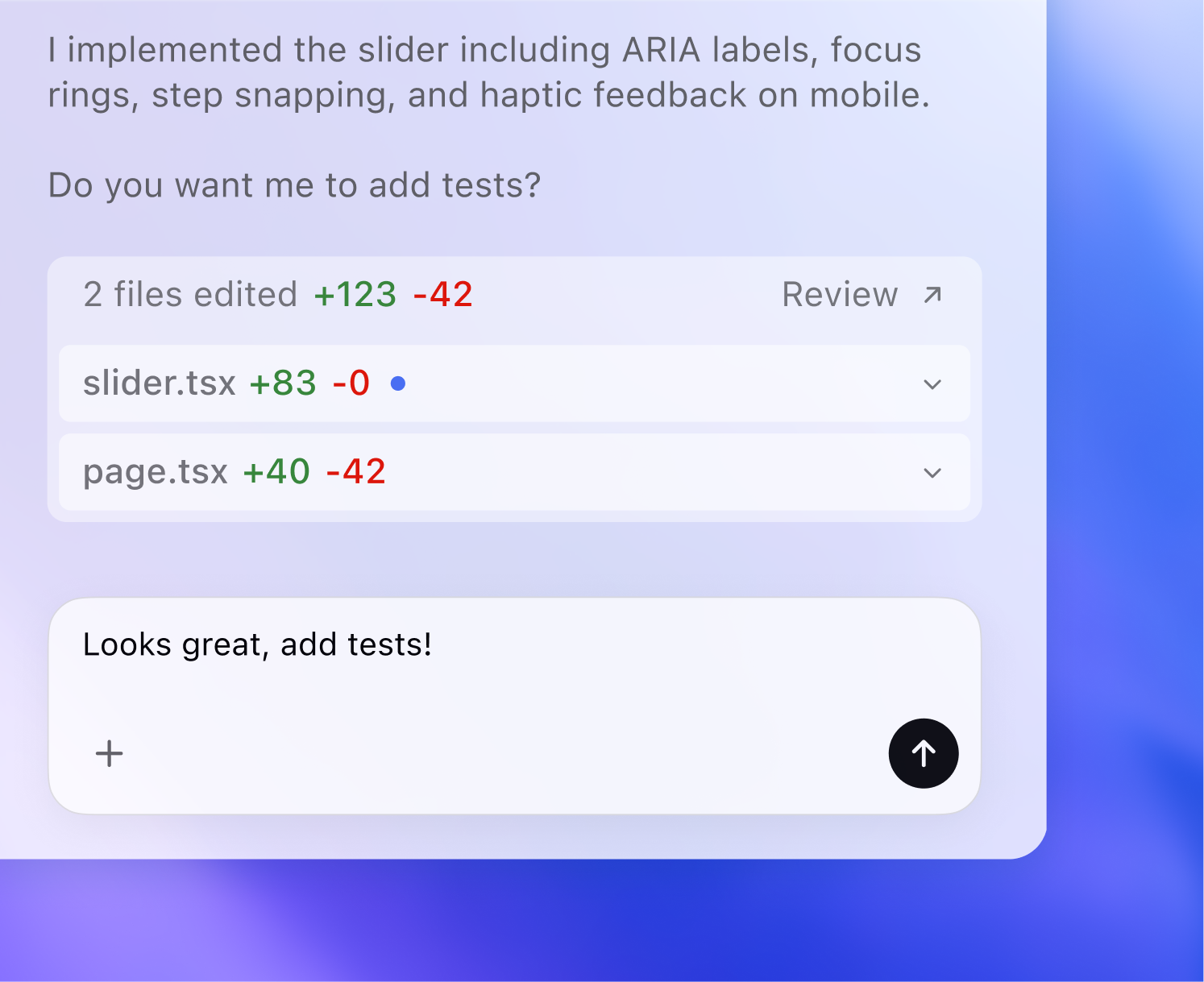
Кому стоит внедрять Codex уже сейчас
Быстрее всего пользу увидят команды, у которых уже есть повторяемые фоновые задачи, нормальный тестовый контур и цена переключения контекста выше, чем цена одного неидеального запуска агента. Это продуктовые и платформенные команды с большим бэклогом мелких инженерных поручений, support и on-call группы, которым нужно быстро сводить контекст по инцидентам, а также компании, где разработчики постоянно разрываются между настоящей архитектурной работой и длинным хвостом рутины.
Им Codex полезен не потому, что "пишет код вместо человека", а потому что съедает часть организационного шума. Он умеет собрать контекст, сделать первую проходку, вернуть diff, лог, тесты и тем самым освободить инженеру голову для принятия решения. Для малых команд или одиночных разработчиков, где проект и так держится в одном сознании и нет сложной операционной прослойки, выигрыш может оказаться заметно меньше.
Где пределы по скорости, доступу и цене ошибки
У Codex есть три жестких ограничения, которые нельзя маскировать красивым анонсом. Первое - скорость. Делегирование удаленному агенту по определению медленнее интерактивного локального редактирования. Второе - доступ. Полезность функции напрямую зависит от того, какой контекст можно дать агенту и на каком тарифе или внутри какой рабочей среды вы вообще можете его использовать. Третье - цена ошибки. Чем ближе задача к продакшн-логике, миграциям, безопасности, биллингу или чувствительным данным, тем дороже становится слепая вера в хорошо оформленный результат.
Именно здесь проходит взрослая граница между agent tooling и demo enthusiasm. Codex может вернуть убедительный diff и аккуратные тесты, но если проект исторически нестабилен, документация дырявая, а команда не привыкла внимательно читать логи и изменения, агент не уменьшит хаос - он просто быстрее доставит его обратно пользователю. Поэтому скорость внедрения должна определяться не тем, насколько впечатляет продуктовая страница, а тем, насколько дисциплинированно живет сама команда.
Кому можно не спешить и где агент скорее мешает
Если у вас маленький проект, почти нет повторяемой рутины, слабый тестовый контур и большая доля работы формулируется словами "ну тут надо самому разобраться", Codex пока не лучший первый выбор. В таком контексте быстрее и дешевле часто работает обычный локальный copiloting-подход: спросить, поправить, сразу проверить в редакторе, не вынося задачу в отдельный жизненный цикл.
То же касается задач, где требования меняются на лету. OpenAI сама указывает, что текущий агент не слишком гибок для резкого course correction в процессе выполнения. Если вы любите постоянно уточнять задачу на ходу, пересобирать решение после каждого нового наблюдения и двигаться маленькими интерактивными шагами, полноценный облачный агент может только добавить лишнюю инерцию.
Что проверить перед пилотом, чтобы не купить дорогой хаос
Перед пилотом Codex стоит проверить пять вещей. Первое: проект должен проходить тесты без ручной магии. Второе: у команды должны быть внятные инструкции, хотя бы в духе AGENTS.md или аккуратного onboarding-документа. Третье: нужно заранее решить, какие классы задач вообще можно делегировать агенту, а какие остаются полностью в руках человека. Четвертое: важно определить метрику успеха - не "всем понравилось", а конкретное сокращение времени на triage, тесты, refactor prep или background fixes. Пятое: нужен нормальный review-процесс, где человек читает diff, смотрит логи и не принимает каждую правку как готовую истину.
TechSvod считает Codex сильным инструментом не из-за очередной модели под капотом, а из-за того, что OpenAI постепенно собирает вокруг нее операционную оболочку. Но это инструмент для зрелого процесса. Там, где его пытаются использовать как магическое сокращение инженерной дисциплины, он почти наверняка разочарует. Там, где дисциплина уже есть, он может действительно снять самую дорогую часть работы - постоянное ручное склеивание контекста.
Обсуждение
Комментарии
Комментарии проходят модерацию перед публикацией. Это защищает обсуждение от спама и случайного мусора.
Загружаем комментарии...