
Что произошло
Google и Google DeepMind представили Gemma 4 12B - среднюю по размеру модель в семействе Gemma 4. Она должна закрыть промежуток между более компактной E4B и крупной 26B Mixture of Experts, сохранив сильные мультимодальные возможности при меньшем требовании к памяти.
По официальному описанию, Gemma 4 12B рассчитана на запуск на потребительских ноутбуках с 16GB VRAM или unified memory. Модель выпущена под лицензией Apache 2.0, а значит разработчики могут использовать ее шире, чем закрытые API-модели.
Почему это не просто еще одна модель
Главная техническая особенность Gemma 4 12B - unified, encoder-free architecture. В обычных мультимодальных системах изображение и аудио часто проходят через отдельные энкодеры, которые переводят данные в представление для языковой модели. Google пишет, что в Gemma 4 12B визуальные и аудиовходы идут напрямую в LLM backbone.
Такой подход должен снижать задержку и потребление памяти. Для пользователя это звучит сухо, но практический смысл понятен: больше задач можно выполнять локально, без постоянной зависимости от облачного API и без передачи данных внешнему сервису.
Что умеет Gemma 4 12B
Модель поддерживает текст, изображения и нативный аудиоввод. Google отдельно отмечает, что это первая mid-sized Gemma с native audio inputs. Для локальных помощников это важно: модель может стать основой не только для текстового чат-бота, но и для сценариев с документами, картинками, голосом и агентными задачами.
Gemma 4 12B также поставляется с Multi-Token Prediction drafters. Это механизм для снижения задержки при генерации: модель может быстрее предлагать несколько токенов вперед, что особенно важно для локального запуска и интерактивных приложений.
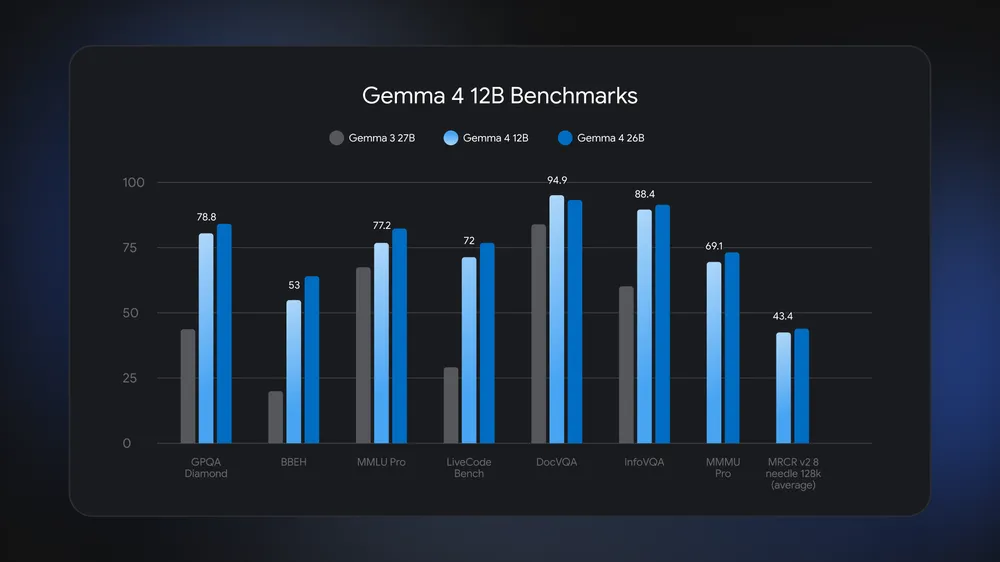
Кому это нужно
Первый очевидный сценарий - локальные AI-агенты для разработчиков. Если модель работает на ноутбуке, ее можно использовать для анализа кода, документов, изображений и рабочих материалов без постоянного подключения к внешней инфраструктуре.
Второй сценарий - edge и privacy-sensitive приложения. Компании, которым нельзя отправлять данные в стороннее облако, получают более практичный вариант открытой модели для внутренних ассистентов, офлайн-инструментов и прототипов.
Третий сценарий - эксперименты с мультимодальными интерфейсами. Нативный аудиоввод и работа с изображениями позволяют строить помощников, которые не ограничены текстовым окном.
Что проверить перед запуском
Первое - реальную конфигурацию железа. Формулировка про 16GB VRAM или unified memory не означает, что любая машина с 16GB системной памяти будет одинаково удобной: скорость и стабильность зависят от ускорителя, quantization, backend и размера контекста.
Второе - поддержку нужного стека. Google указывает на экосистему разработчиков, включая Hugging Face, Kaggle и Google AI Studio, но конкретный production-путь все равно зависит от того, где модель будет работать: локально, на сервере, в приложении или в edge-устройстве.
Третье - ограничения открытой модели. Apache 2.0 дает гибкость, но не отменяет проверку качества, безопасность промптов, оценку hallucinations и тестирование на реальных данных.
Вывод
Gemma 4 12B важна как шаг к более практичному локальному AI. Google не просто уменьшает модель, а пытается сохранить мультимодальность, reasoning и agentic workflows в размере, который помещается в повседневное железо.
Если заявленная эффективность подтвердится в реальных проектах, такие модели могут стать основой для нового слоя персональных и корпоративных AI-инструментов: меньше облачной зависимости, больше локального контроля и быстрее путь от прототипа к рабочему помощнику.
Обсуждение
Комментарии
Комментарии проходят модерацию перед публикацией. Это защищает обсуждение от спама и случайного мусора.
Загружаем комментарии...